Fast growing architectures with serverless and .NET Core
Originally posted on https://tech.just-eat.com/
Serverless technologies provide a fast and independent way for developers to get implementations into production. This technique is becoming every day more popular in the enterprises’ stack, and it has been featured as a trial technique in the ThoughtWorks technology radar since 2017.
The first part of the following article covers some general notions about serverless computing. The second one shows how to build a .NET Core Lambda on AWS using the serverless framework.
Benefits of serverless computing
Serverless technology is part of FaaS (function-as-a-service) technologies family. These kind of technologies are becoming popular with the adoption of the cloud systems. Nowadays, serverless implementations are raised as the preferred technology to use solutions that involve the cloud providers, both private and public.
Furthermore, the typical software services and system perform operations by keeping a massive amount of data in-memory and by writing batches of data in complex data sources.
Serverless, and in general FaaS technologies are designed to keep our system quick and reactive, by serving a lot of small requests and events as quick as possible. Serverless components are usually strongly-coupled with the events provided by the cloud provider where they are running: a notification, an event dispatched by a queue or an incoming request from an API gateway is considered as a trigger for a small unit of computation contained in a serverless component. Therefore, that’s the main reason why the cloud providers pricing systems are based on the number of requests, and not on the computation time.
Moreover, serverless components usually have some limitations on the execution time. Just like every technology, serverless are not suitable for every solution and system. Indeed, it simplifies the life of software engineers. Indeed the lambda deployment cycle is usually fast and, as a developer, we can quickly get new features into production by doing a small amount of work. Furthermore, building components using serverless techniques means that the developer doesn’t need to care about scaling problems or failure since cloud provider cares about that problems.
Finally, we should also consider that serverless functions are stateless. Consequently, each system built on top of this technique is more modular and loosely-coupled.
Serverless pain points
Nothing of this power and agility come for free. First of all, serverless functions are executed on the cloud and they are usually triggered by events that are strongly-coupled with your cloud provider, as a consequence, debugging them is not easy. That’s a valid reason to keep their scope as small as possible, and always separate the core logic of your function with the external components and events. Moreover, it very important to cover serverless code with unit tests and integration tests.
Secondly, just like microservices architectures, which has a lot of services with a small focus, also serverless components are hard to monitor, and certain problems are quite difficult to detect. Finally, it is hard to have a comprehensive view of the architecture and the dependencies between the different serverless components. For that reason, both cloud providers and third-party companies are investing a lot on all-in-one tools which provide both monitoring and systems analysis features.
Experiment using serverless computing
Nowadays more than ever, it is important to quickly evolve services and architectures basing on the incoming business requests. Data-driven experiments are part of this process. Furthermore, before releasing a new feature, we should implement an MVP and test it on a restricted group of
Well, serverless computing provides a way to quickly evolve our architecture without caring about the infrastructure. Serverless light-overhead provides a way to implement disposable MVP for
Implementing AWS Lambda using .NET Core
The following section covers a simple implementation of some AWS Lambdas using .NET Core. The example involves three key technologies:
- AWS is the cloud provider which hosts our serverless feature;
- The serverless framework, which is a very useful tool to get our lambdas into AWS. As a
generic purpose framework, it is compatible with all the main cloud providers; - .NET Core which is the open-source, cross-platform framework powered by Microsoft;
The example we are going to discuss it is also present in the serverless GitHub repository @ the following URL: serverless/examples/
The AWS Lambda project follows this feature schema:
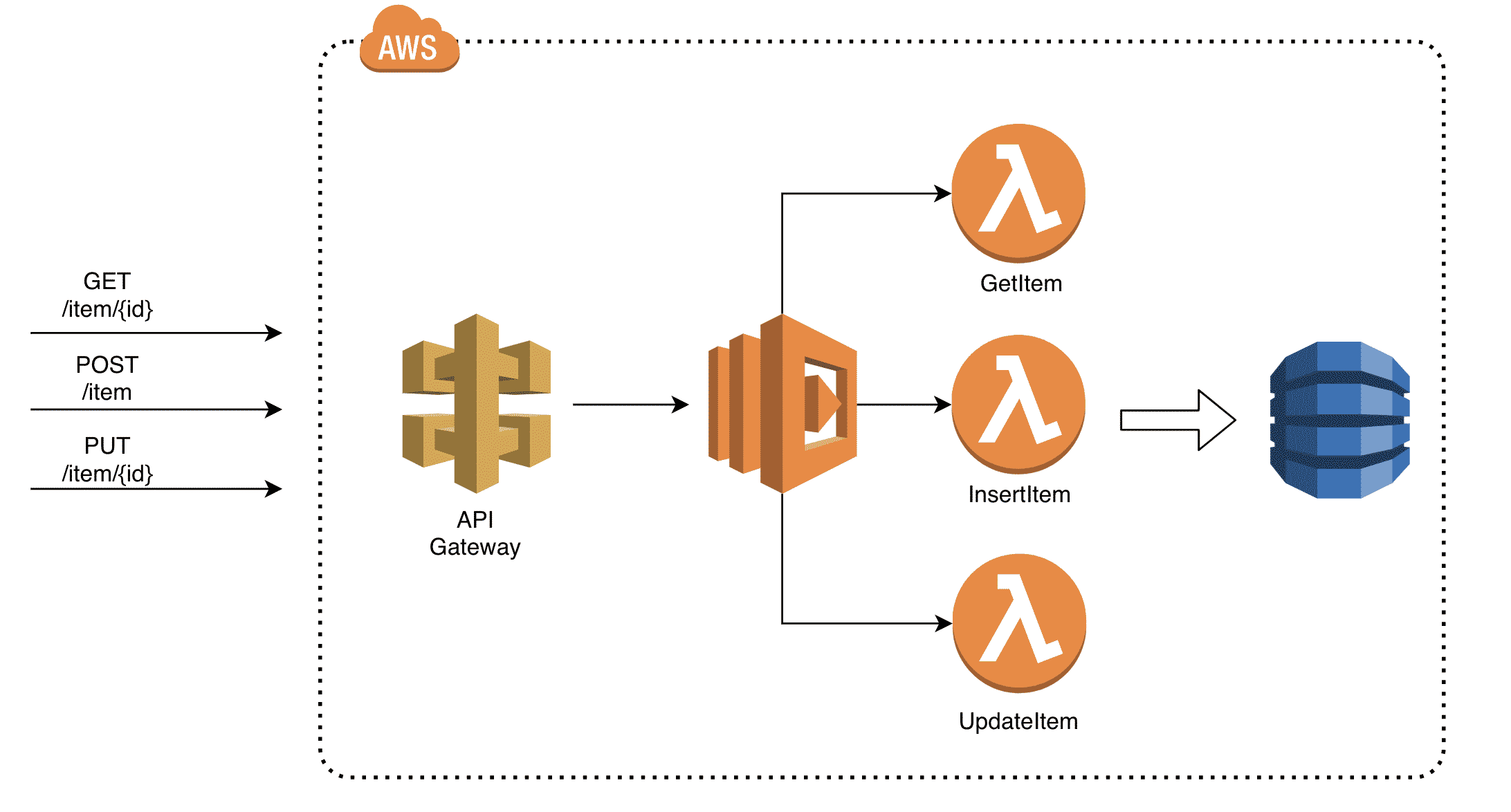
In summary, the feature implements some reading/writing operations on data. An HTTP request comes from the client through the API Gateway, the lambda project defines three functionsGetItemInsertItem UpdateItem
Project structure
The solution we are going to implement has the following project structure:
- src/DotNetServerless.Application project contains the core logic executed by the serverless logic;
- src/DotNetServerless.Lambda project contains the entry points of the serverless functions and all the components tightly-coupled with the AWS;
- tests/DotNetServerless.Tests project contains the unit tests and integrations tests of the serverless feature;
Domain project
Let’s start by analyzing the application layer. The core entity of the project is the Item class which represents the stored entity in the dynamo database table:
The entity fields are decorated with some attribute in order to map them with the DynamoDb store model. The Item entity is referred by the IItemsRepository interface which defines the operations for storing data:
The implementation of the IItemRepository defines two essential operations:
Save, which allows the consumer to insert and update the entity on dynamo;GetByIdwhich returns an object using theidof the dynamo record;
Finally, the front layer of the DotNetServerless.Application project is the handler part. Furthermore, the whole application project is based on the mediator pattern to guarantee the loosely-coupling between the AWS functions and the core logic. Let’s take as an example the definition of the CreateItemHandler:
As you can see the code is totally easy. The CreateItemHandler implements,IRequestHandler and it uses IItemRepositoryinterface. HandlerItemSaveIItemRepository
Function project
The function project contains the entry points of the lambda feature. It defines three function classes, which represent the AWS lambdaCreateItemFunctionGetItemFunction UpdateItemFunction
Let’s dig a little bit into the function definitions by taking as example the CreateItemFunction:
The code mentioned above defines the entry point of the function. First of all, it declares a constructor and it uses the BuildContainer and BuildServiceProvider methods exposed by the Startup class. As we will see later, these methods are provided in order to initialize the dependency injection container. The Run method of the CreateItemFunction is decorated with the LambdaSerializer attribute, which means that it is the entry point of the function. Furthermore, the Run function uses the APIGatewayProxyRequest and the APIGatewayProxyReposne as input and output of the computation of the lambda.
Dependency injection
The project uses the built-in dependency injection provided by the out-of-box of .NET Core. The Startup class defines the BuildContainer static method which returns a new ServiceCollection which contains the dependency mapping between entities:
The Startup uses the ConfigureServices to initialize a new ServiceCollection and resolve the dependencies with it. Furthermore, it also uses the BindAndConfigure method to create some configurations objects. The BuildContainer method will be called by the functions to resolve the dependencies.
Testing our code
As said before, testing our code, especially in a lambda project it is essential regarding continuous integration and delivery. In that case, the tests are covering the integration between theIMediator interface and the handlers. Moreover, they also cover the dependency injection part. Let’s see the CreateItemFunctionTests implementation:
As you can see, the code mentioned above executes our functions and it performs some verification on the resolved dependencies and it verifies that SaveIItemRepository
Deploy the project
Let’s discover how to get the project into AWS. For this purpose, we are going to use the serverless framework. The framework is defined as:
The Serverless framework is a CLI tool that allows users to build & deploy auto-scaling, pay-per-execution, event-driven functions.
In order to get serverless into our project we should execute the following command inside our main project:
npm install serverless --save-dev
Define the infrastructure
By default, the definition of the infrastructure will be placed in serverless.yml
The code mentioned above performs some operations on the infrastructure using cloud formation. The provider node defines some of the information about our lambda, such as the stack name, the runtime and some information about the AWS account. Furthermore, it also describes the roles, and the authorizations of the lambda, e.g., the lambda should be allowed to perform operations on the DynamoDb table. The functions node defines the different lambda functions, and it maps them with a specific HTTP path. Finally, the resource node is used to set the DynamoDB table schema.
Configuration file
serverless.ymlDynamoDbConfiguration__TableName${file(env.configs.yml):dynamoTable}env.configs.yml file:
Final thoughts
The post covers some theory topics about serverless computing as well as a
In conclusion, you can find some example of lambda with serverless in the following repository serverless/examples/
Cover image by Corrado Zeni