Large-Scale Data Quality Verification in .NET PT.1
The quality testing of large data-sets plays an essential role in the reliability of data-intensive applications. The business decisions of companies rely on machine learning models and data analysis; for this reason, data quality has gained a lot of importance. A few months ago, the awslabs/deequ library caught my attention.
The library helps to define unit tests for data, and it uses Apache Spark to support large data-sets. I started to dig into the implementation, and I'm working on porting the library into the .NET ecosystem: samueleresca/deequ.NET.
Why data quality is important?
One thing that I had noticed when I jumped on the machine learning world is that ordinary software engineering practices are not enough to guarantee the stability of the codebase. One of the main reasons is already well-described in the Hidden Technical Debt in Machine Learning Systems paper.
In traditional software projects, the established tools and techniques for code analysis, unit testing, integration testing, and monitoring solve the common pitfalls derived by the code dependencies depts. Although these tools and techniques are still valid on a machine learning project, they are not enough. In a machine learning project, the ecosystem of components and technologies is broader:
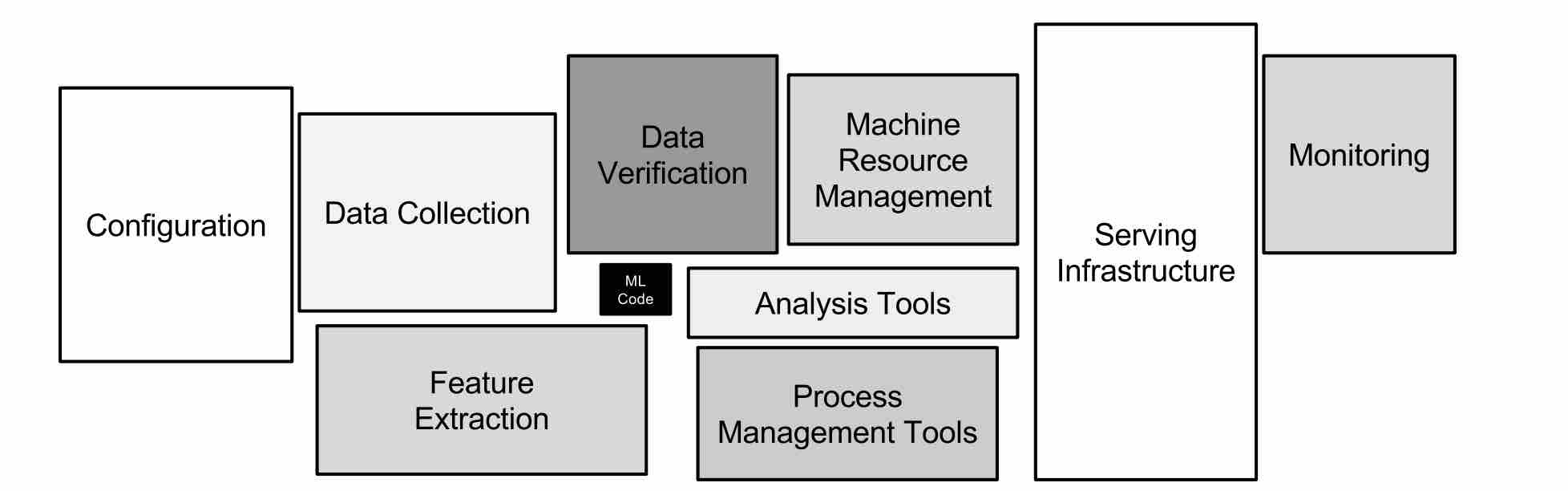
The machine learning code is a minimum part of the whole project. A lot of components are dedicated to the pre-processing/preparation/validation phases, such as the feature extraction part, the data collection, and the data verification. One of the main assertions made by the research paper mentioned above is that the data dependencies cost more than code dependencies. Therefore, the versioning of the upstream data-sets and the quality testing data needs a considerable effort, and it plays an essential role in the reliability of the machine learning project.
Implementation details
The automating large-scale data quality verification research that inspired the deequ library describes the common pitfalls behind the data quality verification and provides a pattern for testing large-scale data-sets. It highlights three data quality dimensions: the completeness, the consistency, and the accuracy of the data.
The completeness represents the degree to which an entity can have all the values needed to describe a real-world object. For example, in the case of relational storage, it is the presence or not of null values.
The consistency refers to the semantic rules of data. More in detail, to all the rules that are related to a data type, a numeric interval, or a categorical column. The consistency dimension also describes the rules that involve multiple columns. For example, if the category value of a record is t-shirt, then the size could be in the range {S, M, L}.
On the other side, the accuracy focuses the on syntactic correctness of the data based on the definition domain. For example, a color field should not have a value XL. Deequ uses these dimensions as the main reference to understand the data quality of a data-set.
The next sections go through the main components that the original deequ library uses, and it shows the corresponding implementation in the deequ.NET library.
Check and constraint declaration
The library uses a declarative syntax for defining the list of checks and the related constraints that are used to assert the data quality of a data-set. Every constraint is identified by a type that describes the purpose, and a set of arguments:
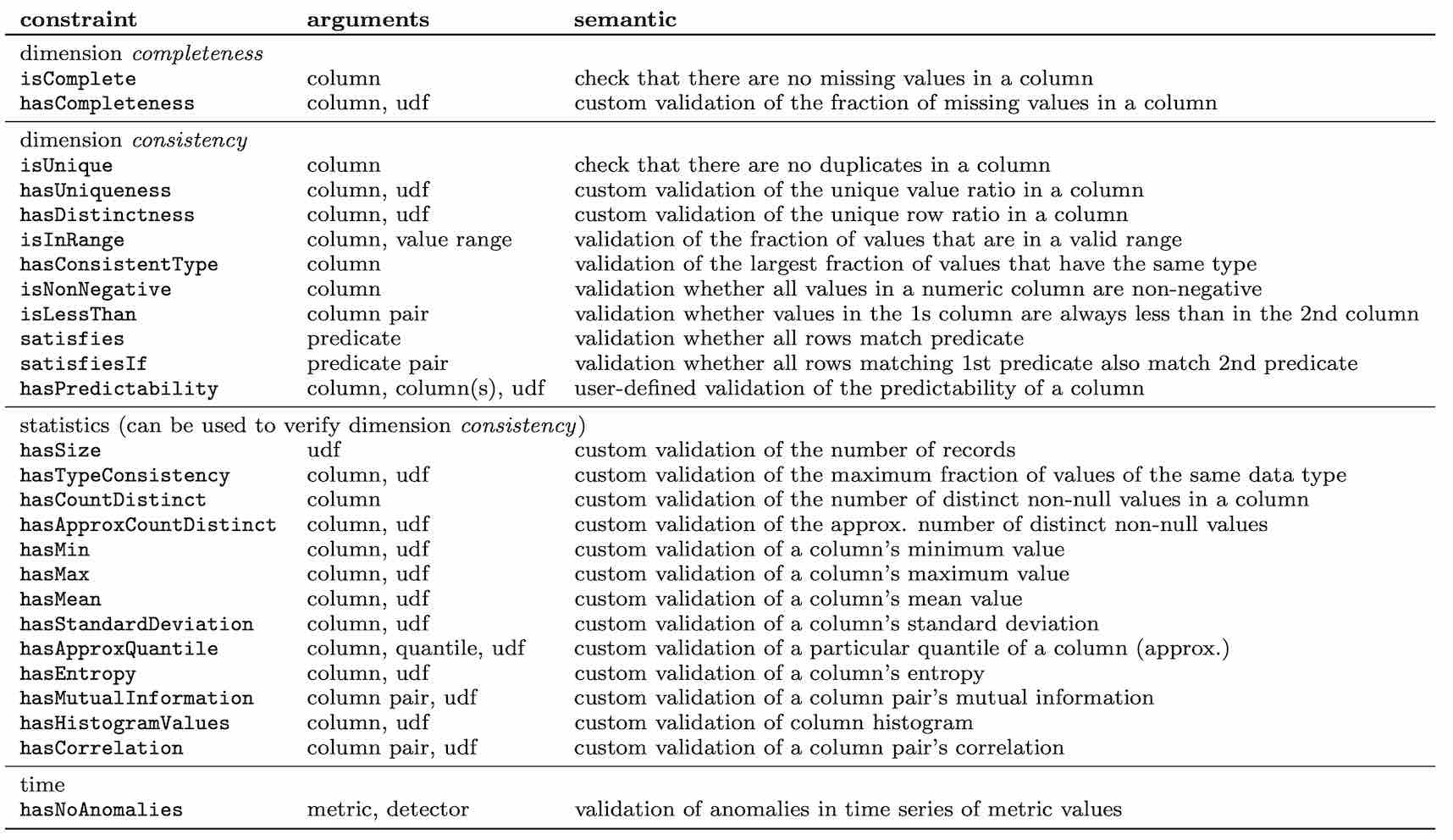
The declarative approach of the library asserts the quality of the data-set in the following way:
The VerificationSuite class exposes the api needed to load the data-set (OnData) and to declare the list of checks (AddCheck).
Every check specifies a description, the list of constraints, and a CheckLevel, which defines the severity of the checks.
Once we declared a list of Check instances, we can proceed by calling the Run method that lazily executes the operations on the data and returns a VerificationResult instance.
Verification output
As mentioned above the verification output is represented by a VerificationResult type. In concrete, this is the core C# definition of the VerificationResult:
The code above introduces the concept of the CheckResult type. The CheckResult class describes the result derived from a check, and it has the following implementation:
For each executed Check, there is an associated CheckResult that contains the Status of the check and a list of ConstraintResults bound with that check. Therefore, once the VerificationSuite has been executed, it is possible to access the actual results of the checks:
The Status field represents the overall status of the VerificationResult. In case of failure, it is possible to iterate every single CheckResult instance and extract the list of ConstraintsResults. Furthermore, we can print out a message for every constraint that is failing and the actual reason for the failure.
At the foundation of each constraint execution, there is an analyzer that interfaces with the Apache Spark APIs. In the deequ.NET implementation the spark API are provided by the dotnet/spark library. In the following section, we will see how the analyzer classes are abstracted from the rest of the layers of the library.
Analyzers
Analyzers are the foundation of the deequ. They are the implementation of the operators that compute the metrics used by the constraints instances. For each metric, the library has multiple analyzer implementations that refer to the Apache Spark operators. Therefore, all the logic for communicating with Spark is encapsulated in the analyzers layer.
More in detail, the library uses the following interface to define a generic analyzer definition:
The interface declares a set of operations part of each analyzer lifecycle:
ComputeStateFromexecutes the computation of the state based on theDataFrame;ComputeMetricFromcomputes and returns theIMetricdepending on the state you are passing in;Preconditionsreturns a set of assertions that must be satisfied by the schema of theDataFrame;Calculateruns the Preconditions, calculates, and returns anIMetricinstance with the result of the computation. In addition to that, it optionally accepts anIStateLoaderand anIStatePersiterinterfaces that can be used to load/persist the state into storage.
Every analyzer implements the IAnalyzer interface to provide the core functionalities needed to run the operations in a distributed manner using the underlying Spark implementation. In addition to the IAnalyzer, the library also defines three additional interfaces: the IGroupingAnalyzer, the IScanShareableAnalyzer, and the IFilterableAnalyzer interface.
The IScanShareableAnalyzer interface identifies an analyzer that runs a set of aggregation functions over the data, and that share scans over the data. The IScanShareableAnalyzer enriches the analyzer with the AggregationFunctions method used to retrieve the list of the aggregation functions and the FromAggragationResult method that is used to return the state calculated from the execution of the aggregation functions.
The IGroupingAnalyzer interface identifies the analyzers that groups the data by a specific set of columns. It defines the GroupingColumns method to the analyzer to retrieve the list of grouping columns.
The IFilterableAnalyzer describes the analyzer that implements a filter condition on the fields, and it enriches each implementation with the FilterCondition method.
Let's continue with an example of the implementation of the MaxLength analyzer. As the name suggests, the purpose of this analyzer is to verify the max length of a column in the data-set:
The class defines two properties: the string Column and the Option<string> Where condition of the analyzer. The Where condition is returned as the value of the FilterCondition method.
The AggregationFunctions method calculates the Length of the field specified by the Column attribute, and it applies the Max function to the length of the specified Column. The Spark API exposes both the Length and the Max functions used in the AggregationFunctions method.
Also, the class implements the AdditionalPrecoditions method, which checks if the Column property of the class is present in the data set and if the field is of type string. Finally, the analyzer instance will be then executed by the ComputeStateFrom method implemented in the ScanShareableAnalyzer parent class:
The IState resulting from the execution of the above method is then eventually combined with the previous states persisted in the memory and converted in a resulting IMetric instance in the CalculateMetric method implemented in the Analyzer.CalculateMetric method implementation.
Incremental computation of metrics
In a real-world scenario, ETLs usually import batches of data, and the data-sets continuously grow in size with new data. Therefore, it is essential to support situations where the resulting metrics of the analyzers can be stored and calculated using an incremental approach. The research paper that inspired deequ describes the incremental computation of the metrics in the following way:
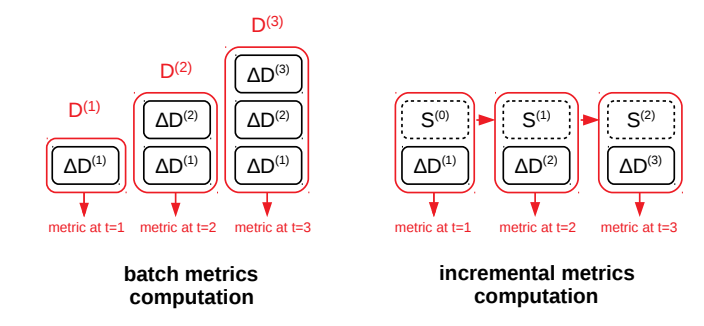
On the left, you have the batch computation that is repeated every time the input data-set grows (ΔD). This approach needs access to the previous data-sets, and it results in a more computational effort.
On the right side, the data-set grows (ΔD) is combined with the state (S) of the previous computation. Therefore, the system needs to recompute the metric every time a new batch of data is processed.
The incremental computation method we described is achievable using the APIs exposed by deequ.
The following example demonstrate how to implement the incremental computation using the following sample:
| id | manufacturerName | countryCode |
|---|---|---|
| 1 | ManufacturerA | DE |
| 2 | ManufacturerB | DE |
| 3 | ManufacturerC | DE |
| 4 | ManufacturerD | US |
| 5 | ManufacturerE | US |
| 6 | ManufacturerG | CN |
and the snippet of code defined here:
The LoadData loads the data schema defined in the table above into three different data sets using the countryCode as a partition key. Also, the code defines a new check using the following constraint methods: IsComplete, ContainsURL, IsContainedIn. The resulting analyzers (obtained by calling the RequiredAnalyzers() method) are then passed into a new instance of the Analysis class.
The code also defines 3 different InMemoryStateProvider instances and it executes the AnalyzerRunner.Run method for each country code: DE, US, CN by passing the corresponding InMemoryStateProvider.
The mechanism of aggregated states (AnalysisRunner.RunOnAggregatedStates method) provides a way to merge the 3 in-memory states: dataSetDE, dataSetUS and dataSetCN into a unique table of metrics. It is important to notice that the operation does not trigger any re-computation of the data sample.
Once we have a unique table of metrics, it is also possible to increment only one partition of the data. For example, let's assume that the US partition changes and the data increase, the system only recompute the state of the changed partition to update the metrics for the whole table:
It is essential to notice that the schema of the data must be unique for every data-set state you need to aggregate. This approach results in a lighter computation effort when you have to refresh the metrics of a single partition of your data-set.
Handle the Scala functional approach
The official awslabs/deequ implementation is written in Sala, which is also the official language of Apache Spark. The strong object-oriented nature of C# adds more difficulties in replicating some of the concepts used by the original Scala deequ library. An example could be the widespread use of the Try and Option monads. Fortunately, it is not the first time that someone ports a Scala library into C# .NET: the Akka.NET (port of Akka) has a handful guide that gives some conversion suggestion for doing that. Akka.NET repository also provides some implementation utils such as the Try<T> and Option<T> monads for C#, which are also used by the deequ.NET code.
Final thoughts
This post described the initial work that I did to port the deequ library into the .NET ecosystem. We have seen an introduction to some of the components that are part of the architecture of the library, such as the checks part, the constraint API, the analyzers layer, and the batch vs. incremental computation approach.
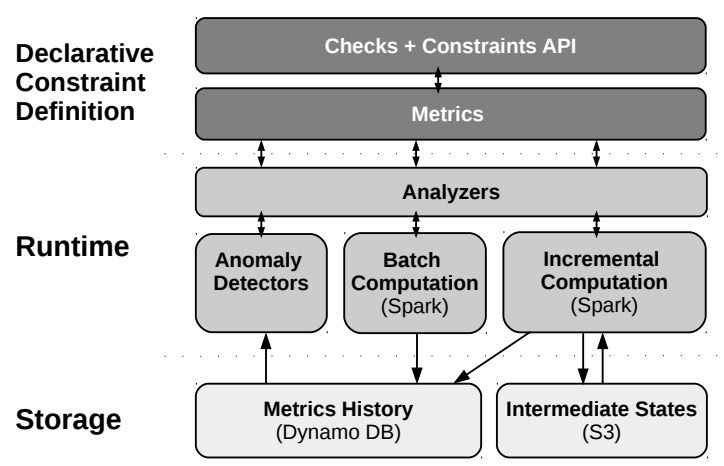
I'm going to cover the rest of the core topics of the library in a next post, such as metrics history, anomaly detectors, and deployment part.
In the meantime, this the repository where you can find the actual library implementation samueleresca/deequ.NET, and this is the original awslabs/deequ library.
References
Automating large-scale data quality verification.