Techniques for fuzz testing
Recently, I have been working on a fuzzer for testing the resilience of a parser. The fuzzer detected some crashes in a parser running on top of well-established production code. That made me realize how critical this testing technique is for the security of a system.
Fuzz testing is a broad topic with many approaches and strategies.
This post summarizes some techniques for fuzz testing and the learnings I have made. It also goes through some fuzz tests running on some cloud-native foundation projects, such as etcd.
The index below summarizes the post sections:
- Anatomy of fuzzing
- Black-box fuzzing
- Coverage-guided fuzzing
- Blackbox fuzzing vs Coverage-guided fuzzing
- Fuzzing in a distributed systems world
- [Use case] etcd fuzzing
- [Use case] .NET fuzzing design proposal
- Democratize fuzz testing
Anatomy of fuzzing
Let's start simple.
The most basic example of a fuzzer might be a function that generates a random value. The generated value is then used as an input for the system under test:
while(true):
# Generation of the fuzzing value
random_value = generate_random()
# Implementation under test
under_test_func(random_value)
The snippet above generates a random value. The under_test_func is executed with the random value for an indefinite amount of iterations. The snippet above might crash given a certain input, depending on the resilience of the under_test_func function.
This is a very basic example of fuzzing. Usually, a fuzzer implementation is more complicated than that.
Before proceeding, let's clarify some terminology by describing an usual fuzzer architecture:
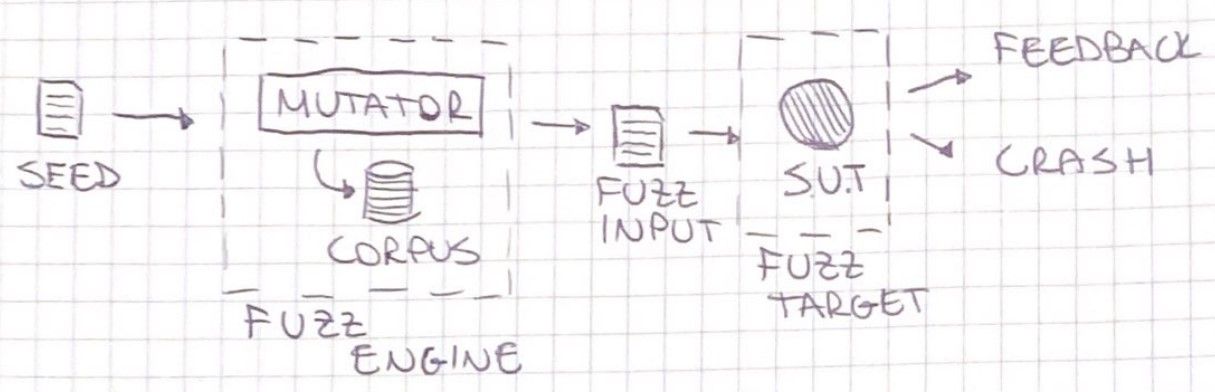
- The seed is a hyperparameter of the fuzzing process. It is the initial input defined by the user that is used as a starting point to generate the fuzzing inputs.
- The fuzz engine finds interesting inputs to send to a fuzz target. Usually, a fuzzing engine includes a mutator actor.
- The mutator generates the corpus manipulating the seed. There are different techniques used by mutators.
- The corpus is a set of inputs that are used by the fuzz target.
- The fuzz input is a single input that is passed to the fuzz target.
- The fuzz target is usually a function that, given a fuzz input, it makes a call to the system under test.
- The system under test is the target of our fuzzing process.
In case the system under test crashes, a new crash report file is generated.
Fuzz target example
The schema above defines a fuzz target. In concrete, fuzz targets usually have an implementation like the one below:
The above code is the target function coming from the LLVM toolchain. The LLVMFuzzerTestOneInput defines the fuzz target function. The fuzz target receives the corpus generated by the mutator.
Note that, every fuzz engine defines its syntax, in general, the function will accept the corpus as parameters.
Black-box fuzzing
In Black-box fuzzing, the fuzz engine does not know anything about the system under test implementation. An example of black-box fuzzing might be a fuzz target that calls an application running on a container exposing an HTTP API.
Below is the schema that describes the scenario:
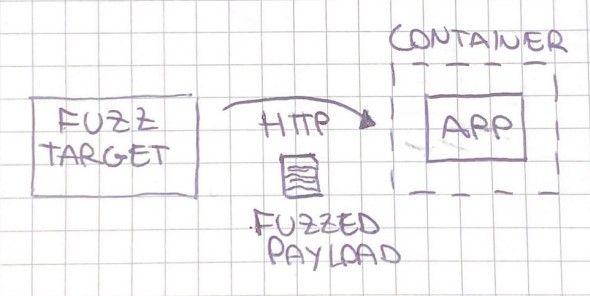
The fuzz target calls the system under test through a client:
The fuzz target and the system under test are running in total isolation. The only information that they share is the network and the input that is sent from one of the fuzz target to the actual system under test.
Keep in mind that fuzzing across the network will slow things down. Futhermore, is hard to detect crashes in the system under test because is running as a separate instance and is not running the fuzzing process. see the Fuzzing in a distributed systems world for more details and solutions.
Coverage-guided fuzzing
Blackbox fuzzing approaches the system under test in a blind way. It doesn't know anything about the internals of the system under testing. Thus, the fuzz input is not tuned to hit every code path. Coverage-guided fuzzing instruments the system under test to gain awareness of the code paths that the fuzz input is covering. More in general, the coverage-guided fuzzing process has two key steps[1]:
- Instrument the system under test to inject tracking instructions at compile time. The purpose is to collect metrics on the code paths covered.
- Keep or discard fuzz inputs depending on the coverage metrics collected.
Coverage-guided fuzzing in depth
The following section describes how AFL++, a widespread fuzzing framework, implements coverage-guided fuzzing[2].
Given the following snippet of code:
x = read_num()
y = read_num()
if x > y:
print x + "is greater than" + y
return
if x == y:
print x + "is equal to" + y
return
print x + "is less than" + y
We can assign an edge for each branching in the code:
0: (A) x = read_num()
1: (A) y = read_num()
2: (A) if x > y:
3: (B) print x + "is greater than" + y
4: (B) return
5: (A) if x == y:
6: (C) print x + "is equal to" + y
7: (C) return
8: (D) print x + "is less than" + y
9: (E) end program
The flow of the code above can be summarized with the following control flow graph, where each branch is an edge of the graph:
┌───┐
┌────┤ A ├────┐
│ └─┬─┘ │
│ │ │
┌─V─┐ ┌─V─┐ ┌─V─┐
│ B │ │ C │ │ D │
└─┬─┘ └─┬─┘ └─┬─┘
│ │ │
│ ┌─V─┐ │
└────> E <────┘
└───┘
AFL++ uses the control-flow graphs in the instrumentation phase by injecting the following pseudo-code in each edge:
cur_location = <COMPILE_TIME_RANDOM>;
shared_mem[cur_location ^ prev_location]++;
prev_location = cur_location >> 1;
The cur_location property identifies the current path within the code using a randomly generated value. The shared_mem takes a count of the amount of time a certain path (source, dest) (given by the XOR cur_location ^ prev_location) has been hit. On top of that, the perv_location value is overridden in each iteration with the right bitshift of the cur_location variable. In this way the injected code keeps track of the ordering: A -> B diff from B -> A.
In this way, AFL++ know which branch has been hit by a specific input and if it is worth continuing for that path.
New behaviours detection
As mentioned above, the coverage algorithm keeps track of two parameters:
- The tuples represent a path in the code
- The number of times that path has been hit (
hit_count)
This information is used for triggering extra processing. When an execution contains a new tuple, the input of that execution is marked as interesting. The hit counts for the execution path are bucketed in the range:
1, 2, 3, 4-7, 8-15, 16-31, 32-127, 128+ // Ranges of hit count.
If the algorithm detects a variation between hit count buckets then the input is marked as interesting. This helps to detect the variations in the execution of the instrumented code.
Even so, it is important to mention that coverage-guided fuzzing does not come for free. Instrumenting the system under test means adding an overhead at runtime. On some occasions, this overhead is not sustainable.
There has been some effort to optimize coverage-guided fuzzing recently. Most of the research focuses on better ways of instrumenting the code[8] and on more meaningful coverage metrics[9].
Blackbox fuzzing vs Coverage-guided fuzzing
We described two fuzzing techniques: black-box and coverage-guided fuzzing. This section gives some guidelines on which type of fuzzing we should use and when.
In general, coverage-guided fuzzing provides better coverage and is more effective. The downside is you need to instrument your target first. This might work well in self-contained libraries, but it might be hard to set up in more complex codebases.
The advice is to examine the system under test and understand the complexity of the codebase:
- For simple and independent codebases, such as libraries, I would focus on coverage-guided fuzzing.
- For complex projects, hard to decompose, black-box fuzzing is the quicker approach, and it can still spot the weaknesses in the system under test. If you are spending a lot of time figuring out how to instrument your code for run fuzzing, you should probably start with a black-box approach.
Fuzzing in a distributed systems world
In the distributed system era, most of the services talks over the network. Fuzzing a network service is not easy for two main reasons:
- In a stateful world, the server can be in various states. On top of that, the exchange usually needs to fit a certain transmission protocol.
- The network slows down the fuzzing.
- It is hard to detect a crash on a system running on a different process.
The general approach for fuzzing over the network is to change the source code to read from stdin instead of relying on the network. [4]
For example, AFLplusplus/utils/socket_fuzzing is an util embedded in AFL++ that provides a way to emulate a network socket by sending input in the stdin.
If changing the source code is not viable, keep in mind that fuzzing over the network is still an option.
aflnet/aflnet: AFLNet provides a suite for testing network protocols. It uses a pcap dump of a real client-server exchange to generate valid sequences of requests while it keeps monitoring the state of the server. The input sequence is then mutated in a way that does not interfere with the rules of the protocol.
microsoft/RESTler provides a way to test a remote-distributed black box [6]. Even if it is not possible to instrument the code of a distributed blackbox, RESTler takes a hybrid approach between a blackbox and coverage-guided fuzzing by measuring the fuzzing effectiveness by introducing a response error type metric. Every time that the distributed blackbox returns an HTTP error type (HTTP status codes from 4xx to 5xx) is considered a crash, and the coverage metrics triggered.
RESTler is HTTP REST-based. What can we do when the system under test utilizes a protocol that is not HTTP? Structure-aware fuzzing becomes handy when you want to compose a message following some rules.
Structure-aware fuzzing
Structure-aware fuzzing [7] is a technique that stands on top of a normal fuzzing process. It can be combined with black-box and coverage-guided fuzzing. Structure-aware fuzzing mutates corpus following a defined structure.
One of the most common tools that implement structure-aware fuzzing is google/libprotobuf-mutator.
This library runs on top of others fuzz engines and mutates the inputs following a protobuf definition. For example, the following proto file defines the structure of a message:
The Msg above can be reused as input for a fuzz target as shown below:
This approach allows defining fuzz inputs based on certain rules. So it excludes all the cases where the corpus provided by the fuzz engine is not compliant with a particular syntax or protocol.
The next section focuses on a concrete example of fuzzing on the etcd-io/etcd OSS project.
[Use case] etcd fuzzing
I recently contributed to etcd fuzzing to solve the following issue: etcd/issues/13617.
The etcd process for receiving requests has two main steps:
- The incoming request goes through a validation step (
validatorstep) - The incoming validated request is applied to the server (
applystep)
The goal was to ensure that API validators reject all requests that would cause panic.
In practice, below is the approach that has been taken:
- Generate an input request with fuzzing
- Send the request to the validator
2.1 If the validator rejects the request then the test pass ✅
2.2 If the validator does not reject the request proceeds with step 3 ⬇️ - Send the request to the apply function
3.1 If the apply function executes without panic then the test pass ✅
3.1 If the apply function panics then the test fails 💀
The following PR implements the approach described above.
Ensure that input validation between API and Apply is consistent #14561.
The implementation uses the new toolchain fuzzing released with Go 1.18, see: go.dev/security/fuzz. Let's start by taking a look at one of the fuzz tests in the PR:
The above implementation shows a fuzz test case for an etcd RangeRequest. The test uses the fuzz capabilities provided by Golang.
FuzzTnxRangeRequestdefines the test case.f.Addoperation adds the seed corpus to the fuzz target.f.Fuzzdefines the fuzz target. It takes as arguments the fuzzed parameters mutate based on the seed corpus.
The fuzz test proceeds by calling the checkRangeRequest function, which implements the validation for the request. In case the validation returns an error, the rest of the test is skipped using t.Skip. In case the request is valid, the test proceeds by calling the apply method (txn.Txn function). The fuzz test will fail if the txn.Txn function panics, otherwise, the test is successful.
The PR also add a fuzzing.sh script that is used to execute the fuzz tests. The script is then embedded in CI using a GitHub Action definition. Below is the core command defined in the fuzzing.sh script:
go test -fuzz "${target}" -fuzztime "${fuzz_time}"
The command executes a specific target (e.g.: FuzzTxnRangeRequest) with a specific fuzztime.
[Use case] .NET fuzzing design proposal
Another open-source contribution I made recently around fuzzing is the following design proposal for the .NET toolchain #273 - Add proposal for out-of-the-box fuzzing. The proposal was highly inspired by the introduction of fuzzing within the Go toolchain. The main reasons that triggered this proposal are:
- The lack of a uniform and easy way to perform fuzz testing in the .NET ecosystem
- Increase the awareness of the fuzzing practice within the .NET consumers. Therefore, increase the overall security of the .NET applications and libraries
The proposal got rejected with some good news: the .NET team is already exploring some possible paths forward, and some internal prototyping effort has already been made.
Final thoughts: Democratize fuzz testing
A few months back, the Cloud Native Computer Foundation (CNCF) went through some effort in the fuzzing space:
Improving Security by Fuzzing the CNCF landscape
The CNCF post goes through a quick introduction to fuzzing and the purposes of this technique. Futhermore, the post shows a list of fuzz tests implemented within the CNCF projects, such as Kubernetes, etcd, and Envoy.
The post's security reports highlight the various crashes has been found in the OSS projects of the CNCF foundation. Surfacing the need for these security practices in the OSS software.
The .NET fuzzing design proposal shown before is tentative to democratize fuzz testing in the .NET ecosystem. The easier is accessing to this security practice, the higher the chance that fuzzing is adopted in the development process. Thus, the shipped software has higher security and resilience standards.
Go 1.18 took a similar approach by including the fuzzing capabilities within the language toolchain. The Go native fuzzing proposal has brought up some interesting discussions available at golang/go/issues/44551.
LLVM took a similar approach long time ago by including libFuzzer in the toolchain.
Democratizing security practices such as fuzzing within the OSS ecosystem is becoming crucial. Especially with the increasing involvement of OSS projects as part of enterprise solutions.
References
[1]Qian, R., Zhang, Q., Fang, C., & Guo, L. (2022). Investigating Coverage Guided Fuzzing with Mutation Testing. arXiv preprint arXiv:2203.06910.
[2]Technical "whitepaper" for afl-fuzz
[3]google/fuzzing
[5]AFLplusplus best_practices
[6]Patrice Godefroid, Bo-Yuan Huang, and Marina Polishchuk. 2020. Intelligent REST API data fuzzing.
[7]Going Beyond Coverage-Guided Fuzzing with Structured Fuzzing - Black Hat
[8]S. Nagy and M. Hicks, "Full-Speed Fuzzing: Reducing Fuzzing Overhead through Coverage-Guided Tracing," 2019 IEEE Symposium on Security and Privacy (SP), 2019, pp. 787-802, doi: 10.1109/SP.2019.00069.
[9]L. Simon and A. Verma, "Improving Fuzzing through Controlled Compilation," 2020 IEEE European Symposium on Security and Privacy (EuroS&P), 2020, pp. 34-52, doi: 10.1109/EuroSP48549.2020.00011.