Notes on threading
This post shares some personal notes related to multithreading in C#. Although it describes several concepts of multithreading in C#, some of the topics can be similar in other typed languages. The following notes are the results of readings, interview prep that I had in the past years. The post implements the concepts on a concrete LRUCache example. The code related to the post is available on GitHub.
Below the topics described in this post:
- Low-level API - thread initialization
- Thread Pool - thread initialization
- Thread pool from a Task perspective
- Thread safety and sychronization
- Example of signaling between threads
Low-level API - thread initialization
There are different ways of initializing threads. .NET provides a different level of abstractions for the thread initializations. First of all, an intuitive approach is to declare a new Thread instance in your code:
using System.Threading;
namespace Blog.LRUCacheThreadSafe
{
class Program
{
static void Main(string[] args)
{
new Thread (myMethod).Start();
}
}
}
The Thread class exposes properties to check the state of the instance of the thread. At the same time, it is possible to alternate the state of the thread by calling the methods exposed by the instance, e.g., the Start() and Stop() methods start and stop the execution of the threads. It also is possible to wait for the completion of a thread by using the Join() method exposed by the Thread instance:
using System;
using System.Threading;
namespace Blog.LRUCacheThreadSafe
{
class Program
{
static void Main(string[] args)
{
Thread thread = new Thread (myMethod);
thread.Start();
thread.Join();
Console.WriteLine ("myMethod execution ended");
}
}
}
The Join() method provides a way to wait until the execution of the t instance is completed. After that, the executions proceed on the main thread, in this case, the Program.Main method. Every time we use the Join() method, the calling thread is blocked.
One important fact to notice is that the new Thread initialization does not use the thread pool, we can verify that by calling the IsThreadPoolThread property exposed by the t object.
Because of the lack of abstraction over the low-level nature of the Thread class, Microsoft introduced multiple abstractions over this class. Most of them rely on the thread pool to improve the efficiency of the code. Furthermore, it is strongly suggested to use the higher-level APIs to achieving a parallel workflow in .NET.
As we will see later, the Thread class is still useful to cover some of the core concepts related to the synchronization and messaging between threads.
Thread Pool - thread initialization
The creation process of the new Thread comes with a considerable overhead in terms of time complexity and resources. For this reason, Microsoft built an abstraction that delegates the management of the OS threads to the Thread Pool implemented in the CLR. One of the Thread pool main feature is to optimize the creation and destruction of the threads by re-using the threads. Therefore, it is more suitable for short-running tasks.
The Thread Pool way of working can be described in the following way:
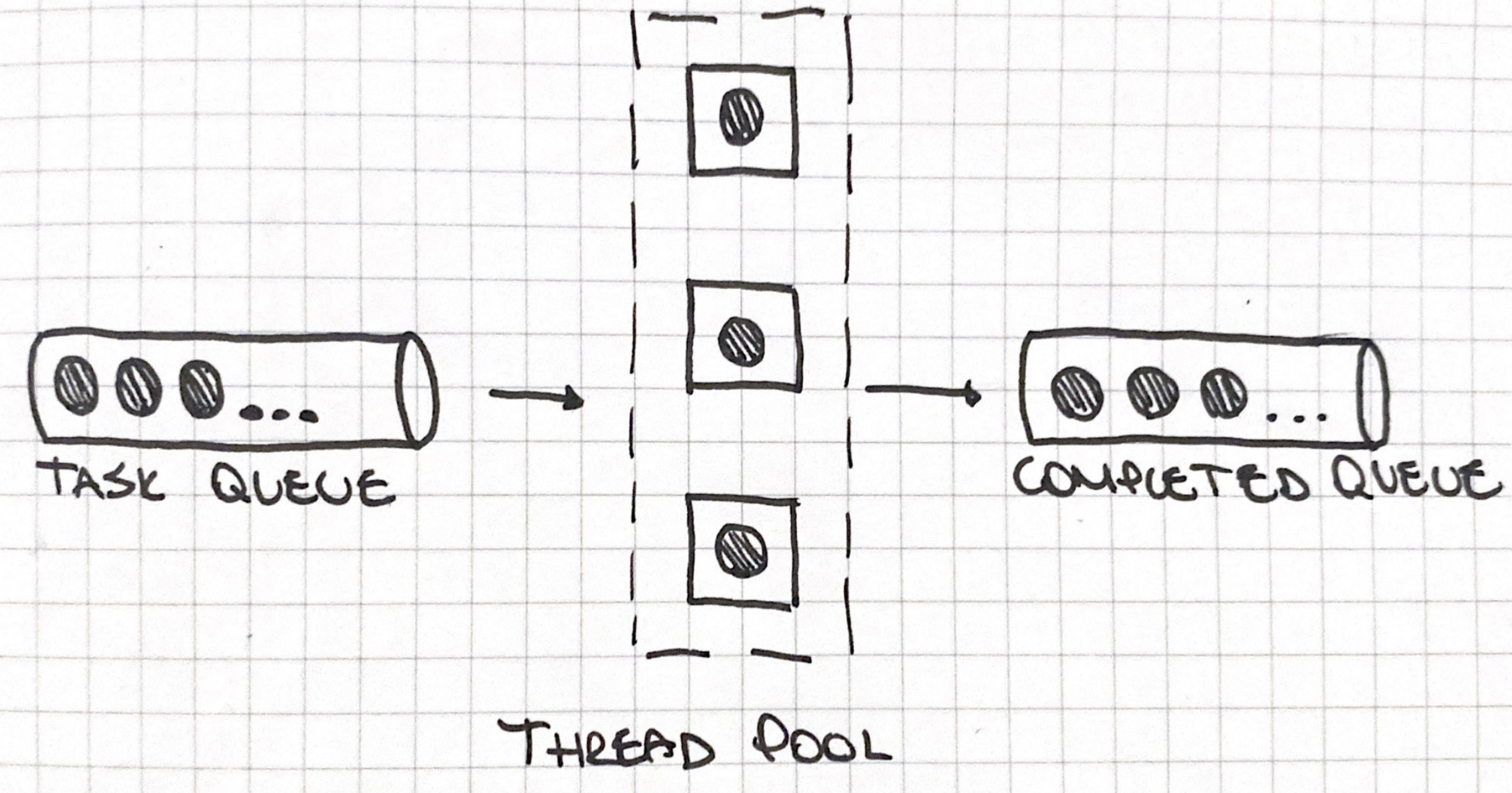
There is a queue of tasks that are processed by N threads present in the Thread pool. The queuing operation is implemented using the following method:
ThreadPool.QueueUserWorkItem(() => { ... });
More in detail, the queuing process uses the thread injection and retirement algorithm described in this post. which proceeds with the following workflow:
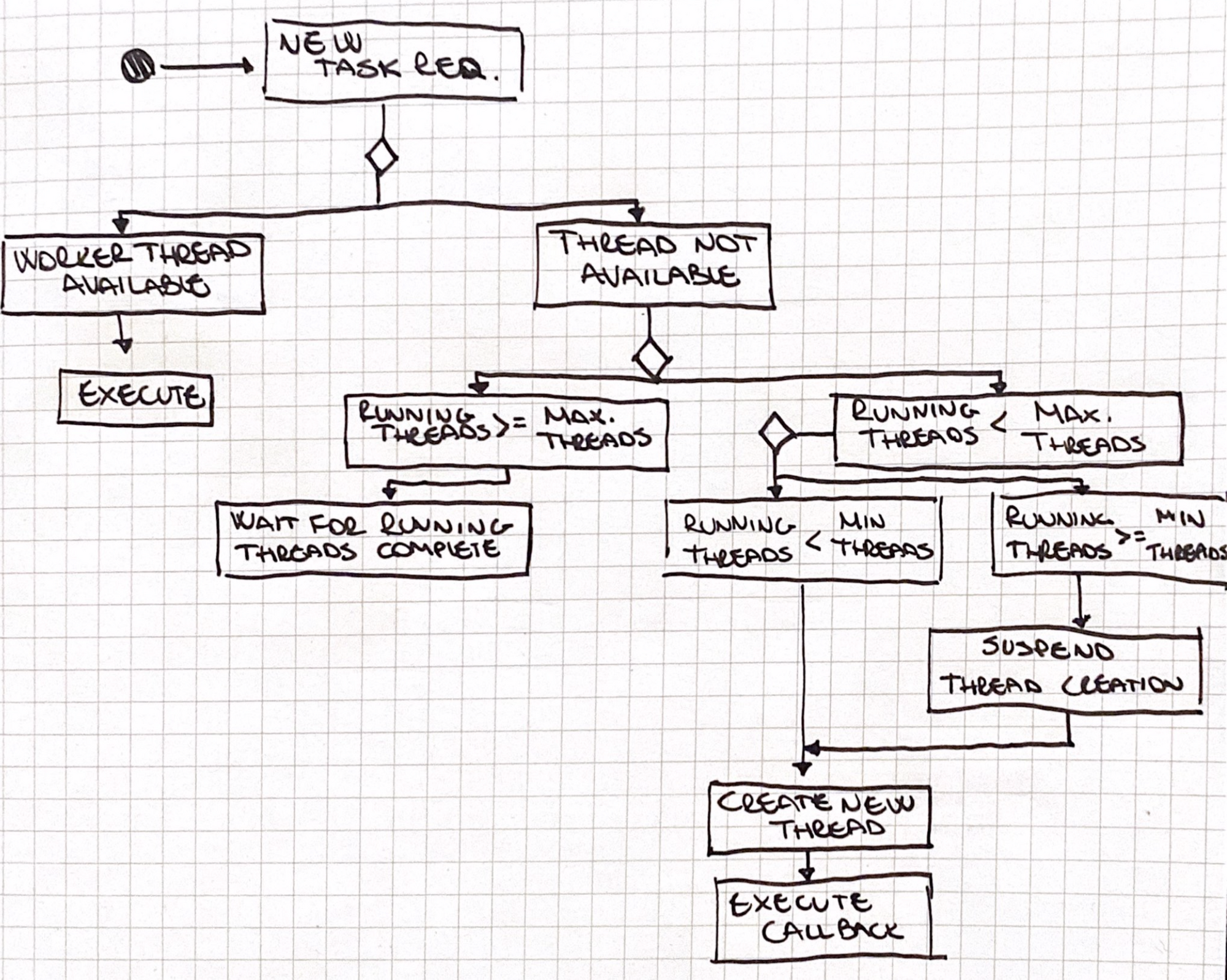
When a new task is queued, and there are no available threads, the ThreadPool verify that the running threads have reached the maximum number of threads and it waits until a running thread is completed. Otherwise, it checks if the amount of the running threads is less than the minimum, and in that case, it creates a new thread.
Furthermore, if the number of running threads is equal to the allowed minimum, then it suspends the creation of new threads.
The thread pool can be configured with a maximum / minimum number of threads using the following approach:
ThreadPool.SetMaxThreads(int workerThreads, int completionPortThreads);
ThreadPool.SetMinThreads(int workerThreads, int completionPortThreads);
To understand these methods is also essential to distinguish between two different types:
- the
workerThreadsparameter sets the number of worker threads which refers to all the CPU-bound threads used by the application logic; - the
completionPortThreads(not used in UNIX-like OS) parameter sets the amount of I/O threads which refers to all the I/O-bound operations that use resources other than CPUs;
These two types are commonized with the introduction of the System.Threading.Tasks namespace.
Thread pool from a Task perspective
Starting from CLR 4, the Thread pool way of queuing Tasks from System.Threading.Task perspective has been optimized to improve the handling of multiple asynchronous nested tasks. The CLR 4 introduced a double queue architecture.
- global queue used by the main thread to queue tasks in a FIFO order;
- local queues, once for each thread worker, it is used to queue the work in the context of a specific task, and it works like a stack (LIFO order);
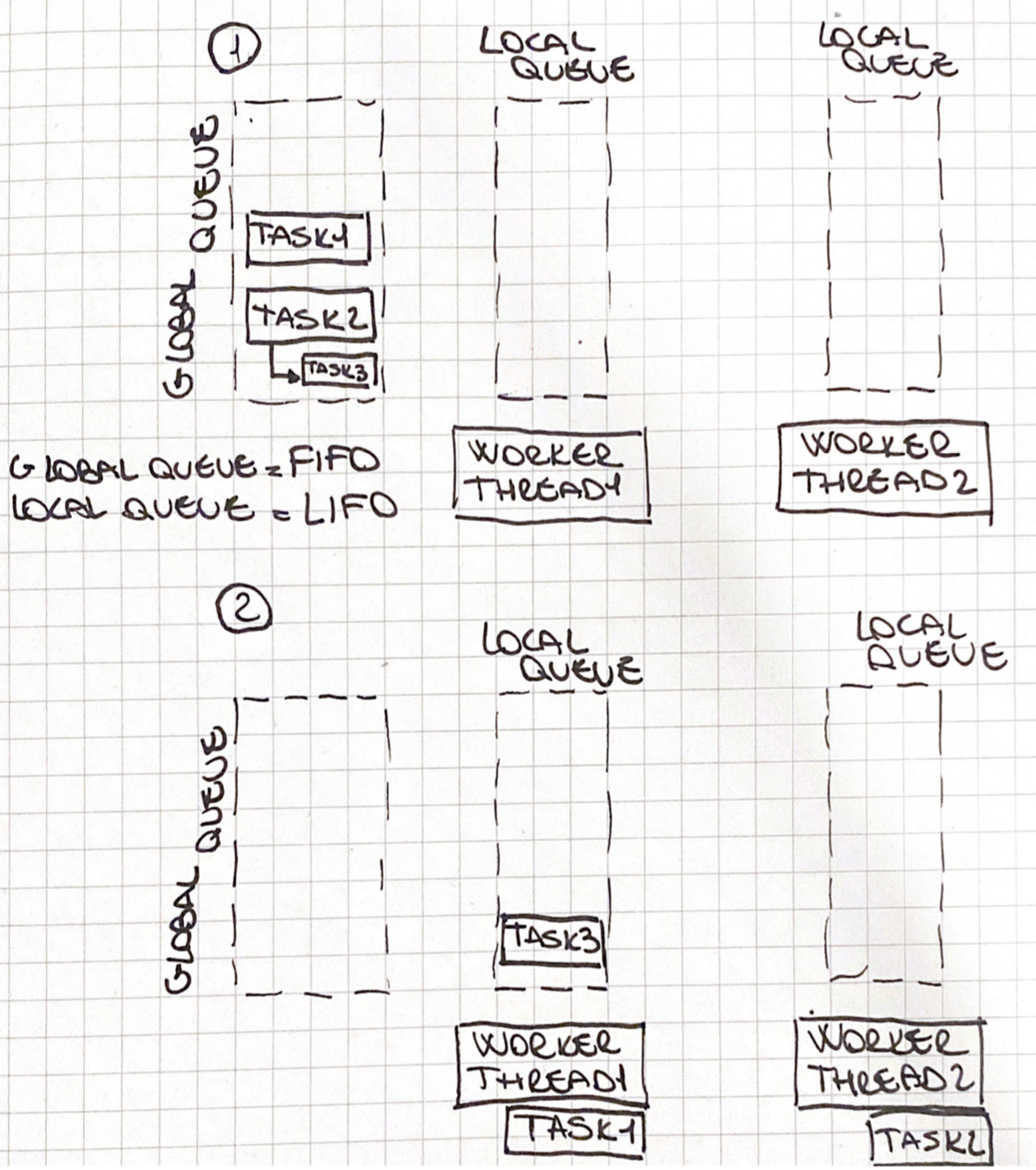
The above image (1) describes the process of queuing two tasks: Task1 and Task2. Task2 has a nested task, called Task3. The Task1 and Task2 are queued in the global queue and picked up respectively by the Worker Thread1 and the Worker Thread 2, while Task3 is queued in the local queue of the Worker Thread 1 (2).
Now two things can happen:
- if the
Worker thread 1ends processingTask 1before the other worker threads are free, it is going to pick up theTask 3from the local queue. - if the
Worker thread 2end processingTask 2before the other workers, it going to look into the local queue for another task, if the local queue is empty, it will proceed by checking the global queue, and finally, if the global queue is empty it going to pick up theTask 3from the local queue of theWorker Thread 1, this is defined as work-stealing.
Recently the corefx of .NET Core has implemented the possibilty to direct the creation of the new thread pools to the local queues in the ThreadPool.QueueWorkItem method: dotnet/corefx/pull/24396.
Starvation issue
The Thread pool starvation became more frequent with the increase of the need for high-scale async services. The Thread pool starvation main symptom is your service that is not able to handle the increasing number of incoming requests, but you can still see the CPUs are not fully utilized.
This symptom can point your attention to 3rd party components calls. Furthermore, it is also possible to see a method call that takes a long time to complete the execution.
However, sometimes the stall can be caused by the lack of threads that can run the next step in servicing the request, so it merely stalls, waiting for the availability of thread. This time is registered as execution time for the asynchronous method; therefore, it seems like that the operation randomly takes longer than it should.
There is the following blog post of Criteo Labs that explain in detail the issue. Let's take the example they describe in the post:
The above implementation uses the System.Threading.Task APIs to simulate a thread starvation issue through some blocking calls. Mainly, this set of rules describes the enqueuing behaviors:
-
Every time you execute
Task.Factory.StartNewfrom the main thread, the task will be added to the global queue; -
The
ThreadPool.QueueWorkItemadds the execution on the global queue unless you specify thepreferLocalparameter, see #24396; -
The
Task.Yieldinstructions add theTaskto the global queue unless you are not on the default task scheduler; -
Every time you execute
Task.Factory.StartNewfrom inside a worker thread, it will add the task to local queue; -
In all other cases, the
Taskis scheduled on the local queue;
In the code above, the main thread spawns a new Process method execution every 200 msec in the global queue. The Process methods trigger another thread in the local queue using the Task.Run method, and it waits for the completion of the execution. When the thread pool spawns a new thread, it follows this check sequence, as mentioned previously:
- check if there are items in its local queue;
- check if there are items in the global queue;
- check the local queues of other threads (work-stealing);
The Producer method has already queued another set of tasks in the global queue, and the ratio of the creation of new threads in the global queue is higher than the creation of new threads, there is a saturation of tasks.
You can see it by executing and checking the output of the application, that in most cases is blocked:
Ended - 18:38:20
Ended - 18:38:20
Ended - 18:38:20
Ended - 18:38:21
Ended - 18:38:21
Ended - 18:38:21
Ended - 18:38:22
Ended - 18:38:22
Furthermore, we can see the number of threads of the process that increase during the execution time, without stabilizing, and the CPU usage that stays low:

In this case, the Process method is executed every second and is queued into the global queue. The Main method spawns more threads more quickly than the capacity of the thread pool to generate new threads. Therefore the application reaches a condition of starvation. Because the bottleneck is derived by the global queue, a common thought could be to de-prioritize it, see #28295, but the work-stealing between local queues come with a cost. In some cases, it may cause performance degradation in the system. Asynchronous operations are becoming more common these days; it is essential to pay attention to this kind of issue and try to avoid mixing asynchronous with synchronous stacks. Moving from synchronous stack to async can be dangerous, see the post-mortem Azure DevOps Service Outages in October 2018.
Thread safety and synchronization
A snippet of code is thread safe when called by multiple threads does not cause race conditions. Race conditions mainly happen when multiple threads share the same resources. It is crucial to highlight that:
- every variable stored in the stack is thread-safe, since the stack is related to a single thread;
- everything else, stored in the heap can potentially be shared by multiple threads;
Furthermore, we can take as reference some simple examples. Everything declared as a local variable is in general thread-safe:
In this case, the variable has a primitive type, and it is locally declared. Therefore, it is out-of-box thread-safe because it is stored in the stack.
Let's proceed with the following example that declares a reference type inside the method:
The pointer stored in the stack refers to an instance of the object stored in the heap memory. Since the object is never returned and it is only used by the Initializer and the Handler methods, you can declare it thread-safe. Let's consider the situation where the Handler assign the object to an attribute of the class, as follow:
The attributes of a class are stored by default along with the object in the heap. Therefore the above Handler(string value) method is not thread-safe; if it is used by multiple threads can lead you into a race condition situation:
ThreadUnsafeClass threadUnsafeClass = new ThreadUnsafeClass();
new Thread(() => threadUnsafeClass.Handler("value1")).Start();
new Thread(() => threadUnsafeClass.Handler("value2")).Start();
On the opposite side, you can use techniques such as immutability in order to avoid race conditions:
new Thread(() => new ThreadUnsafeClass().Handler("value1")).Start();
new Thread(() => new ThreadUnsafeClass().Handler("value2")).Start();
In the above snippet the Thread types are dealing with separate instances of the ThreadUnsafeClass type, so the two threads will not share the same data.
Another way to avoid race conditions in the code is the use of the locking constructs provided by the framework.
LRUCache and locking constructs
The locking constructs are used to coordinate the usage of shared resources. To describe the lock constructs provided by the .NET Core, we going to use the following example:
The above code describes a common LRU Cache implementation. The code defines a Dictionary called _records, which will contain the id -> value of each cache record. The _freq attribute stores the order of the last-accessed records by referring to the indexes of the record. The LRUCache<T> type defines two methods: Get, Set, and a _capacity attribute that represents the capacity of the LRU cache. In the example, we are ignoring some concurrent collections provided by the CLR.
The following tests verify the behaviors implemented in the LRUCache<T>:
The tests lock some of the behaviors of the LRUCache by replicating the following actions:
- the cache removes least accessed records when the capacity is reached;
- the cache stores correctly the integer values;
- the cache prioritization changes when the cache reads a record;
Let's suppose that we want to access the collection from multiple threads, as follow:
The code mentioned above executes a set of Task on the same LRUCache instance, the execution will result in the following exception:
Unhandled exception. System.InvalidOperationException: Operations that change non-concurrent collections must have exclusive access. A concurrent update was performed on this collection and corrupted its state. The collection's state is no longer correct.
at System.Collections.Generic.Dictionary`2.FindEntry(TKey key)
at System.Collections.Generic.Dictionary`2.get_Item(TKey key)
at Blog.LRUCacheThreadSafe.LRUCache`1.Set(Int32 key, T val) in /Users/samuele.resca/Projects/Blog.LRUCacheThreadSafe/Blog.LRUCacheThreadSafe/LRUCache.cs:line 52
at Blog.LRUCacheThreadSafe.Program.<>c__DisplayClass0_0.<Main>b__0() in /Users/samuele.resca/Projects/Blog.LRUCacheThreadSafe/Blog.LRUCacheThreadSafe/Program.cs:line 13
at System.Threading.Tasks.Task.InnerInvoke()
at System.Threading.Tasks.Task.<>c.<.cctor>b__274_0(Object obj)
Each Task element runs the Set operation on the LRUCache instance that results in a race condition between multiple Tasks. To avoid this kind of exception, we can proceed by implementing a locking process using the constructs available in .NET. The lock operator guarantee that a single thread can access the snippet of code in the parenthesis. This type uses the Monitor.Enter and Monitor.Exit constructs and it requires a reference type instance that works as synchronization object; Therefore, we can wrap our Get and Set methods in the following way:
Now the LRUCache<T> class defines a _locker object that it is used to perform the locking operation. Every reference type can be used as a synchronization object; in the case above, we are using an object type. The lock constructs wrap the implementation of the Get and Set methods to guarantee the access at only one thread simultaneously.
An alternative way is to use the Semaphore / SemaphoreSlim constructors. They implement a number-based restriction which guarantees the concurrent access to the specific number of threads defined in the constructor, by implementing a queuing mechanism on the code to execute. The Semaphore type constructor accepts a name to use in case you need a multi-process lock. The SemaphoreSlim has been introduced recently: it is optimized for parallel-programming, and it exposes the asynchronous methods, but it does not support the cross-process. The following implementation describes the use of the SemaphoreSlim constructor:
The initialization of the _sem attribute defines the number of concurrent threads that can access the resources: in this case, we set a maximum of 1 thread per operation. Furthermore, we use the try {} finally {} block to manage the locking/unlocking of the resources:
- the
_sem.Wait()stops the thread until the stop requirements of the semaphore definition are met; - the
_sem.Release()instruction exit from the semaphore and proceed with the release of the lock;
It is important to notice that the try {} finally {} block is used in order always to ensure that the code releases the semaphore. Once we have entered the semaphore using _sem.Wait() we need always to call the _sem.Release() method, otherwise the application code will be stuck waiting for the semaphore to be released. e.g.:
In the case described above, the _sem.Release() method is only called in the main execution branch of the application. Therefore, the application will be stuck in case the condition at line 7 (!_records.ContainsKey(key)) is satisfied because the execution will never exit from the semaphore.
Another synchronization constructor that enables a more granular approach in controlling the threads is the ReaderWriterLockSlim. This type provides a way to differentiating locking depending on the type of access performed on the resource. In most cases, instances are thread-safe for reading operations but not for concurrent updates. The ReaderWriterLockSlim provides the EnterReadLock / ExitReadLock methods that allows the other concurrent reading operations, and it provides the EnterWriteLock / ExitWriteLock methods that excludes both the reading and writing operation on a specific resource. To use this kind of process, we can proceed in the following way:
The code mentioned above describes the implementation of the ReaderWriterLockSlim into the Get method of the LRUCache type. The lock is applied in the following way:
- Apply the read lock using
EnterReadLockmethod; - Check if the
_recordsmember contains the key; - Exit from the read lock using
ExitReadLock; - Apply the write lock using the
EnterWriteLockmethod; - Update the table of the frequencies, by moving the element in the last position;
- Exit from the write lock using
ExitWriteLock; - Finally, it returns the
CacheValueby entering in the read lock;
As you can see, there are a couple of steps where it happens a transition between the read lock and the write lock. For this reason, the ReaderWriterLockSlim introduced a new lock type that can be activated by using the EnterUpgadeableReadLock method. The upgradable lock starts as a normal read lock, and it can be upgraded to write lock, e.g.:
The code above mentioned uses the EnterUpgadeableReadLock to initialize the read lock on the Get method, and it upgrades the lock to the write mode when it needs to force the writing mode:
- Apply the read lock using
EnterReadLockmethod; - Check if the
_recordsmember contains the key; - Apply the write lock using the
EnterWriteLockmethod; - Update the table of the frequencies, by moving the element in the last position;
- Exit from the write lock using
ExitWriteLock; - Finally, it returns the
CacheValueand exit from the read lock;
The above implementation scale-up or scale-down the lock restriction depending on the actual access type that is running as of next instruction.
Example of signaling between threads
The following example implements some multithreading testing on the LRUCache<T> implementation. The test uses the ManualResetEventSlim class to coordinate multiple concurrent operations on the LRUCache type. The ManualResetEventSlim can be used as a signaling event between threads; furthermore, it blocks and unblocks the execution of the threads.
The following code describes the implementation of the test:
The above test class declares a should_supports_operations_from_multiple_threads test method. The method performs the following operations:
- Split the test into two phases by declaring the
setPhaseandgetPhaseusing theManualResetEventSliminstance type; - Initializes an array of type
Thread. For each thread in the array, it performs aSetand aGetoperation on theLRUCache<T>type, and it uses theManualResetEventSliminstances for blocking the threads; - Once the array of
Threadis declared, the code calls thesetPhase.Set()method to trigger the_cache.Setoperations. The same approach is taken for the_cache.Getoperations;
Furthermore, each thread proceeds as follow:
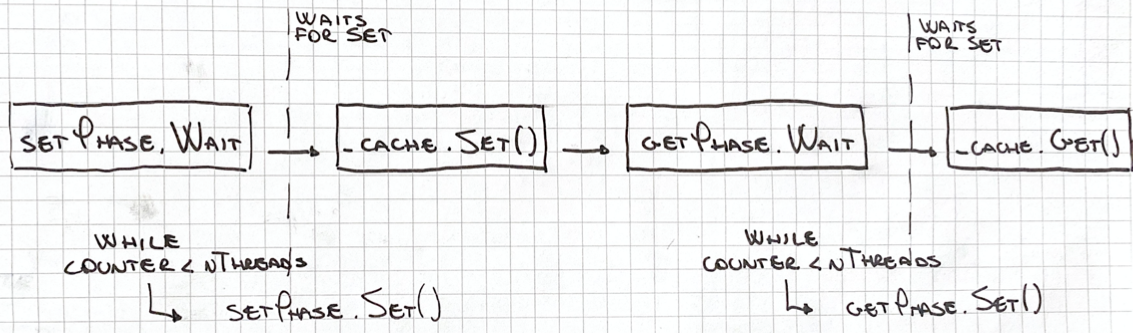
The threads wait until the setPhase.Set method is called by the main thread; at this point, every thread runs the _cache.Set operation on the LRUCache<T> instance. The main thread keeps the count of the executed set by incrementing a progressCounter. The main thread proceeds by calling the getPhase.Set method once the progressCounter reaches the number of initialized threads.
In the following way, we are going to have a nThreads that will execute the _cache.Set operation at the same time; after that, they will be blocked until the last set operation is performed. Finally, they _cache.Get method will be called to read all the values.
As expected, the implementation executes all the _cache.Set operations before the _cache.Get execution.
Depending on the type LRUCache<T> we initialize, the test fails or not.
Because the LRUCache type doesn't support multithreading we will receive a System.InvalidOperationException. If we use the LRUCacheReaderWriterLock type, we will receive the following outcome from the _outputConsole helper:
Another important aspect to consider is that we are incrementing the progressCounter in the following way:
Interlocked.Increment(ref progressCounter);
Because the counter is declared outside the scope of the threads, and multiple threads use it, we are using the Interlocked.Increment dependency to force an atomic operation. The Interlocked.Increment accepts as a reference a variable to increment using an atomic approach.
Although, read and writes on int can be considered as atomic:
CLI shall guarantee that read and write access to properly aligned memory
locations no larger than the native word size (the size of type native int) is atomic when all the write accesses to a location are the same size.
ECMA-335 standard
the increment operation is not atomic; for this reason, the Interlocked constructor can be helpful in these cases.
Final thoughts
The post provides some of the notions around threading in C#. It describes topics like starvation, event handling, blocking synchronization, and it applies these concepts to an LRUCache implementation example. You can find the code on the following repository. The information provided in this post are the foundation of some of the topics that are NOT covered like Dataflow, Channels, Blocking collections, and more in general, all the Task parallel library provided by .NET.
Below some of the references related to the post: